Local RAG in Microsoft Word: using AnythingLLM + LM Studio


In my recent post, I explored AI-assisted writing by using LM Studio in Microsoft Word, utilizing my local Word Add-in (GPTLocalhost) as a bridge. During the experiment I realized that Retrieval-Augmented Generation (RAG) was an important aspect to consider. In this follow-up story, I’ll demonstrate how to enable local RAG in Microsoft Word using AnythingLLM and LM Studio as the backend. Local RAG means that all data processing happens on your computer, without any data leaving your device. This approach has several benefits, including increased security and reduced reliance on cloud services.
How to set up local RAG itself has been explained well recently in several sources, such “Local RAG with AnythingLLM and Llama 3.1 8B” by Michael Ruminer, “How to Implement RAG locally using LM Studio and AnythingLLM” by Fahd Mirza, and “How to enable RAG on an AMD Ryzen™ AI PC or Radeon Graphics Card” by AMD, etc. Given this background, I will focus on integrating the RAG backend with Microsoft Word through the local Word Add-in instead and test what I can do with AnythingLLM. In this way, you can compare the local RAG approach with similar functions in Microsoft Copilot in Word. According to this post “Using Microsoft Copilot in Word” by Holger Imbery: if you have a Copilot for Microsoft365 license, you can reference up to three of your files to help guide Copilot’s drafting. Use the “Reference your content” button or type “/” followed by the file name in the compose box. This feature only accesses the files you select.
When using AnythingLLM as local RAG, in contrast, you can reference as many files as your hardware allows. The number of files that can be saved to the vector database in AnythingLLM is not limited. Moreover, the Chat mode in AnythingLLM offers two configuration options: Chat and Query. The Query mode will provide answers only if document context is found. The Chat model will provide answers with the LLM’s general knowledge and document context that is found. As the following screenshot shows, this flexibility allows users to tailor their interactions with AnythingLLM to suit their specific needs and preferences.
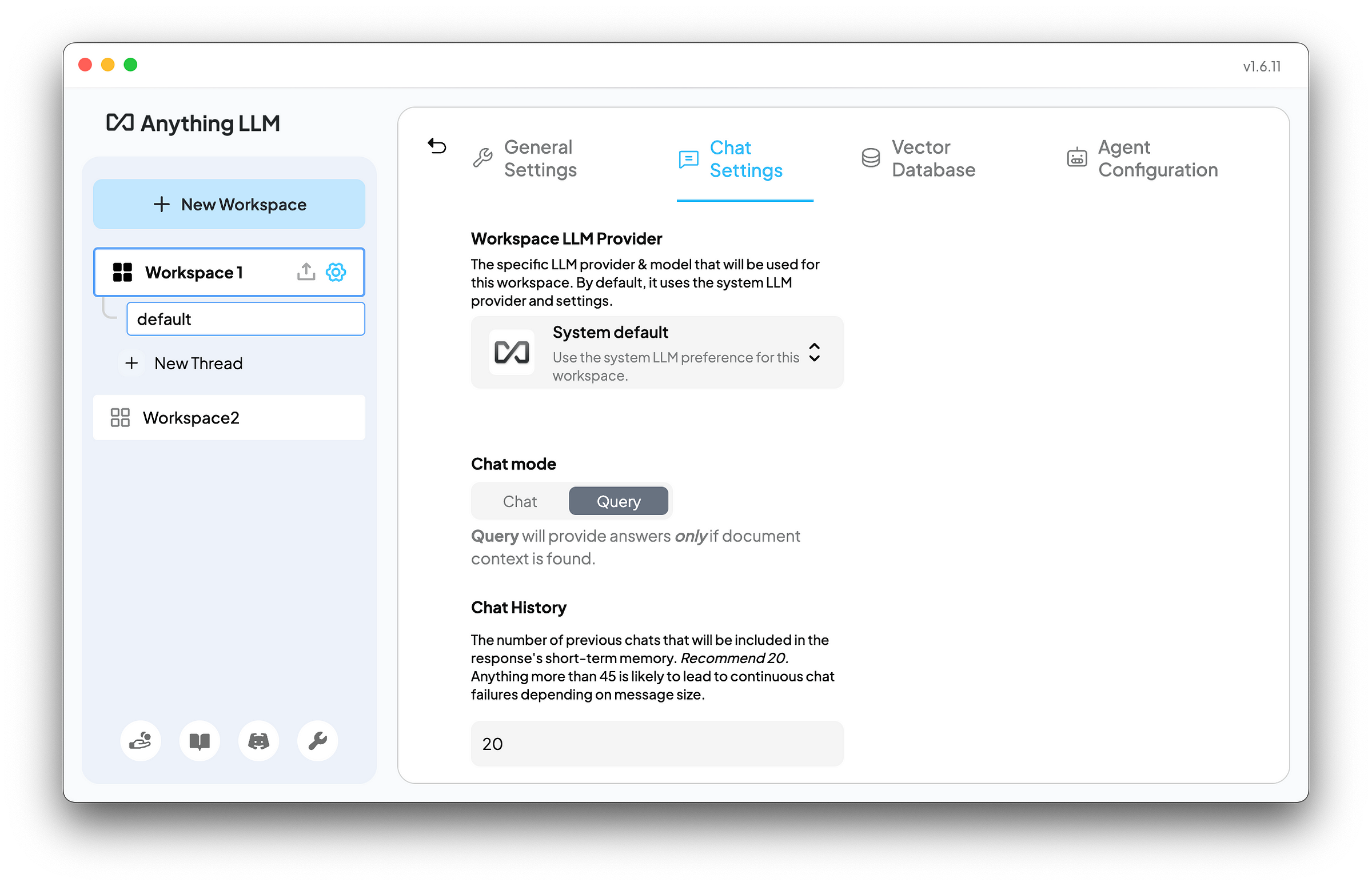
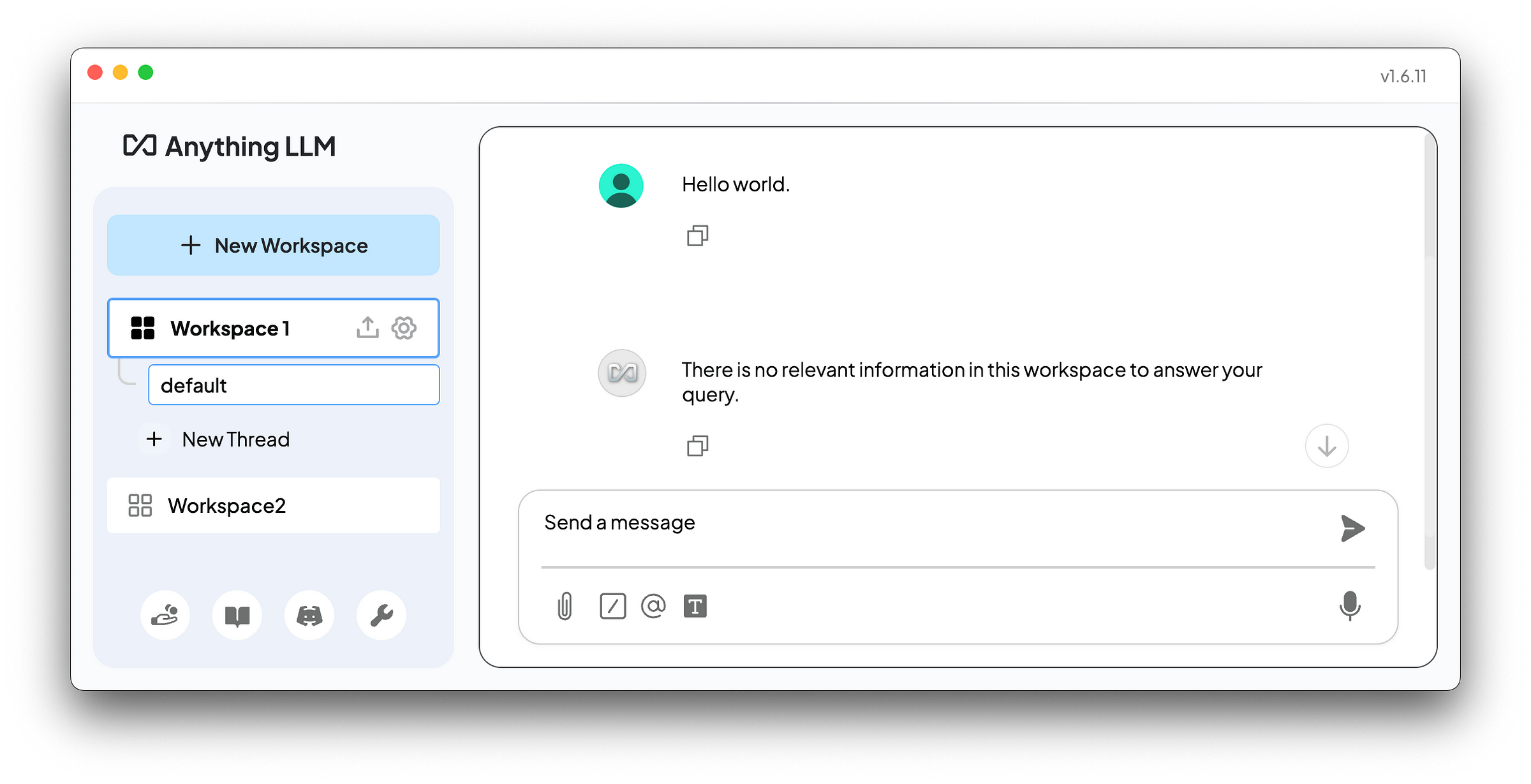
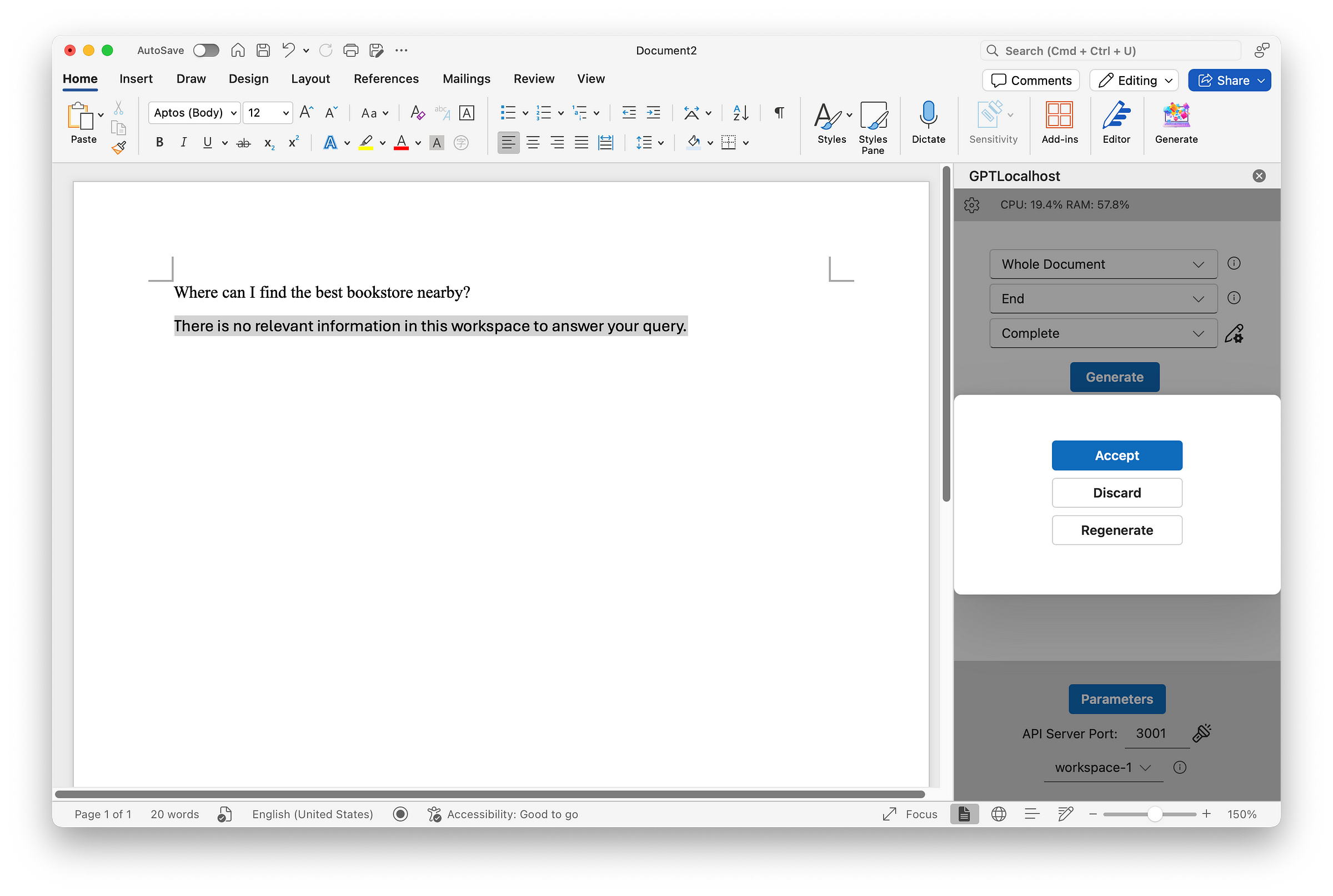
For example, if no documents or data are uploaded to the vector database in AnythingLLM, the language model will reply “There is no relevant information in this workspace to answer your query.” as follows.
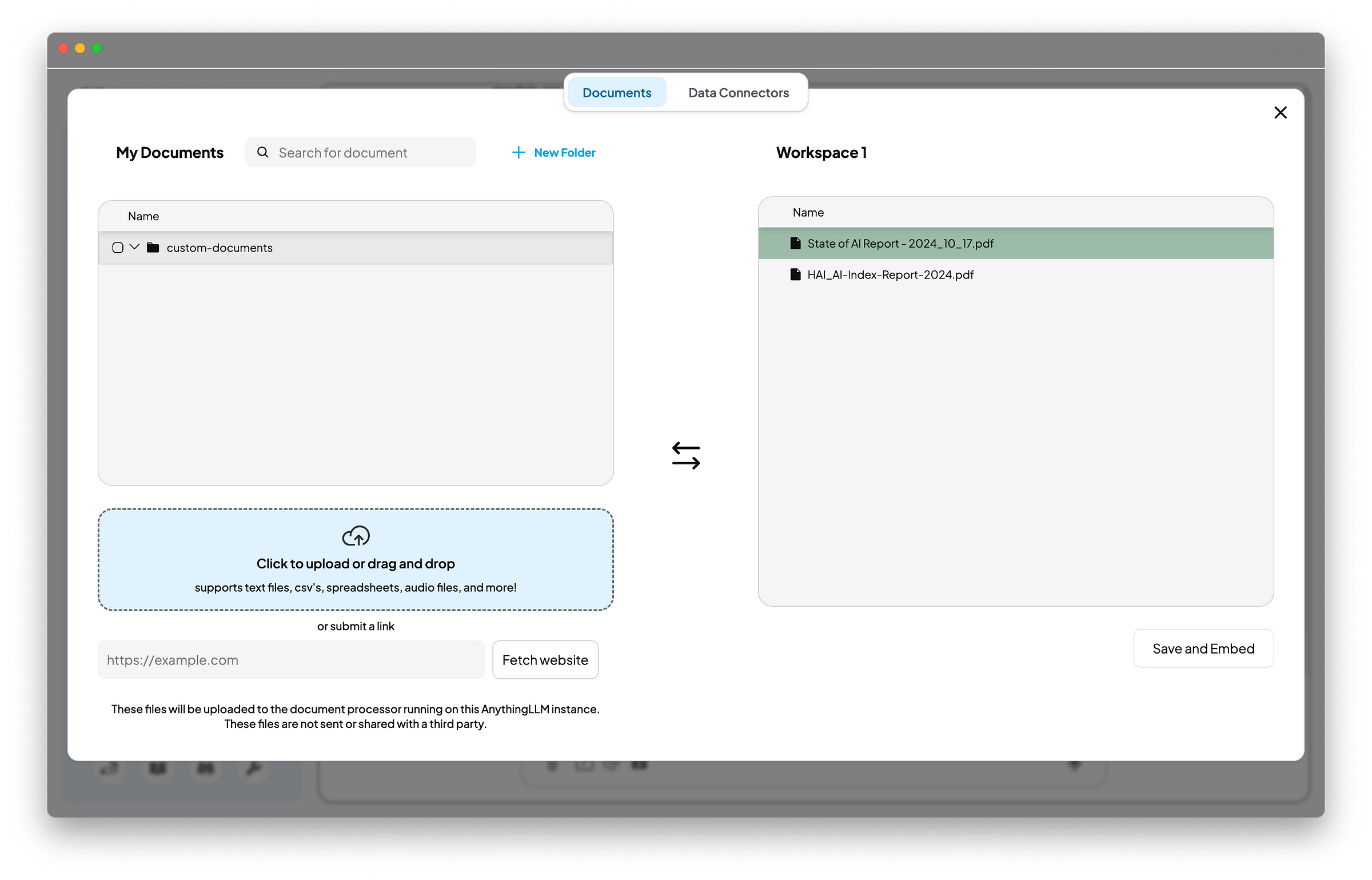
To test the effectiveness of RAG, I downloaded the 2024 AI Index Report by the Stanford Institute for Human-Centered Artificial Intelligence and the State of AI Report by produced by AI investor Nathan Benaich and Air Street Capital. The downloaded files are in PDF format, uploaded them to my workspace in AnythingLLM, and embedded them into the vector database, shown as below. I also switched AnythingLLM into Query mode since the objective is to test its RAG effectiveness.
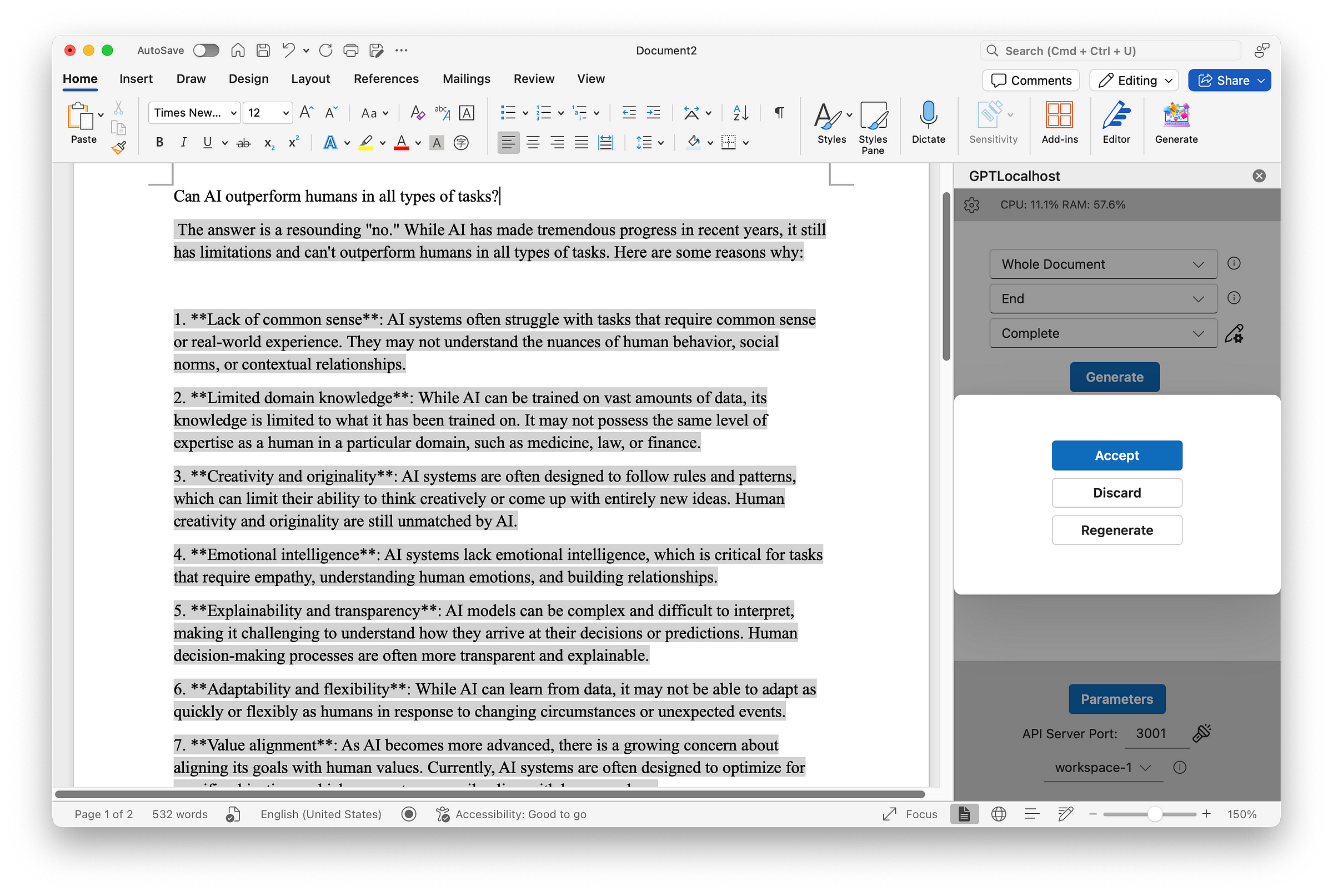
Two scenarios were tested: one positive and one negative. The positive scenario involved simulating a conversation with PDF files by typing questions into my Word document and instructing the model to continue writing through my local Word Add-in. This setup mimicked a chatting interface, allowing users to interact with the model in a convenient way. The question asked was: Can AI outperform humans in all types of tasks? Upon clicking the “Generate” button, the model produced the following response:
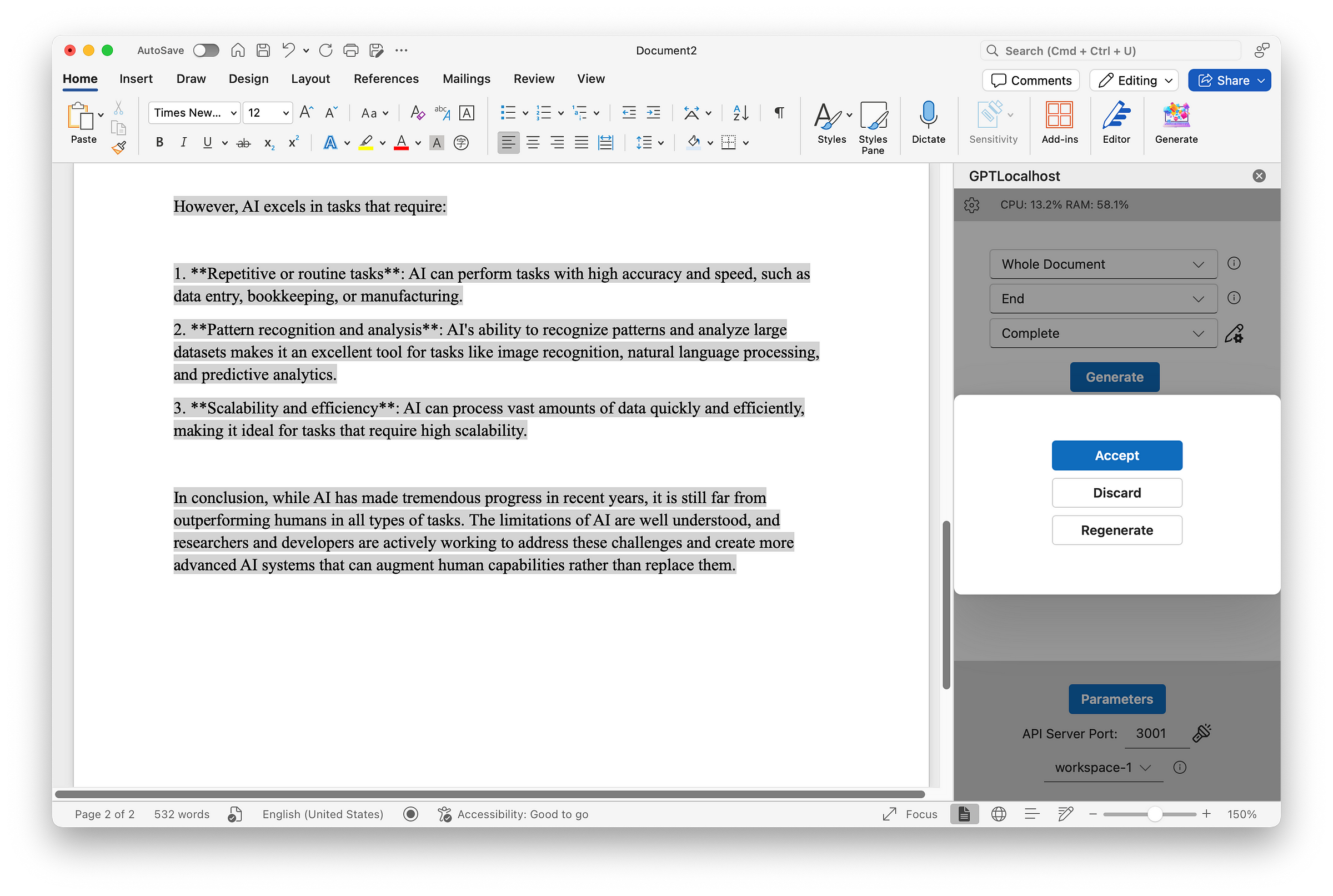
The negative scenario involved asking an out-of-scope question, which resulted in the following response from the model indicating “no relevant information”.
Based on these two test cases, it appears that RAG performs seemingly well under the Query mode, with responses reasonably relevant within the scope of uploaded documents in vector databases. However, the question of whether these responses are truly grounded remains an open challenge. Another intriguing question for further exploration is the effectiveness of RAG for creative writing, which warrants additional experiments and consideration for a future post. Stay tuned.